
Giriş Merhaba, iyi günler! Bu yazımda sizlere Nest.js, Redis, PostgreSQL ve Prisma kullanarak geliştirdiğim Blog.io uygulamasında, API performansını üst seviyeye taşımak için neler yapabileceğimizi veya nelerden kaçınmamız gerektiğini anlatmak istiyorum.
Senaryo Tanımı Nest.js ile geliştirdiğim Blog.io uygulamasında, özellikle gerçek hayat senaryolarına uygun olarak backend tarafından sunulan API’ları Artillery.io kullanarak Docker ile sunucumuzda test edeceğiz. Ayrıca, bu testler için Postman’i de kullanacağız. Önce temel kavramları açıklayarak başlayacağız; ardından geliştirdiğim uygulama özelinde yapılan iyileştirmelere geçeceğiz.
API Performansını Üst Seviyeye Taşımanın Yolları
Bu bölümde, API performansını artırmak için kullanabileceğimiz çeşitli teknikleri detaylı bir şekilde inceleyeceğiz. Bu teknikler, uygulamalarımızın hızını ve verimliliğini artırmak için kritik öneme sahip olup, doğru uygulandığında kullanıcı deneyimini de iyileştirebilir.
A) Select Kullanımı: Veritabanı sorgularında gereksiz alanları döndürmek, hem performansı olumsuz etkileyebilir hem de gereksiz veri transferine yol açabilir. Bu durumu önlemek için select kullanımı oldukça önemlidir. Select, yalnızca ihtiyaç duyulan alanları belirterek, veritabanından gelen yanıtın boyutunu küçültmenize ve böylece API'nizin performansını artırmanıza yardımcı olur. Aşağıdaki örnekte, sadece gerekli olan kullanıcı bilgilerini ve profil resminin URL'sini çekmek için select nasıl kullanılır, bunu görebilirsiniz:
const user = await this.prismaService.user.findUnique({
where: { uuid: uuid },
select: {
uuid: true,
email: true,
role: true,
name: true,
ProfileImage: {
select: {
imageUrl: true,
},
},
},
});
Bu şekilde, veritabanından sadece gerekli olan veriler çekilerek performans artışı sağlanabilir ve gereksiz veri işleme yükü azaltılabilir.
B) Caching (Önbellekleme): Veritabanı sorgularını minimize etmek ve uygulamanın performansını artırmak için sık kullanılan verileri bir in-memory veri tabanında, örneğin Redis’te, saklamak etkili bir yöntemdir. Bu teknik, özellikle çok sık değişmeyen veriler için idealdir. Redis, bu tür durumlarda düşük gecikme süresi ve yüksek performansıyla öne çıkar.
Test senaryolarına geçmeden önce, Redis ile önbellekleme işlemini nasıl gerçekleştirebileceğimize dair bir örnek üzerinde duralım. Örneğin, kullanıcılara ait profil bilgilerini veritabanına her seferinde sorgulamak yerine, bu bilgileri Redis’te saklayarak daha hızlı bir erişim sağlayabiliriz. Bu sayede, aynı verilere tekrar tekrar ihtiyaç duyulduğunda veritabanı sorgusu yerine Redis’ten okuma yaparak performans artışı elde edebiliriz.
async getUser(uuid: string): Promise<UserDto> {
// Kullanıcıyı Rediste arama işlemi
const cachedUser = await this.redisService.get(`user:${uuid}`);
if (cachedUser) {
return JSON.parse(cachedUser);
}
// Eğer kullanıcı yok ise veritabanından al
const user = await this.prismaService.user.findUnique({
where: { uuid },
select: {
uuid: true,
email: true,
role: true,
name: true,
ProfileImage: {
select: {
imageUrl: true,
},
},
},
});
// Kullancıyı redise kaydet
await this.redisService.set(`user:${uuid}`, JSON.stringify(user), 'EX', 3600); // 1 saat geçerli olacak şekilde
return user;
}
C) Pagination (Sayfalama): Büyük veri setleri ile çalışırken, tüm verileri tek bir sorguda çekmek hem performans hem de kullanıcı deneyimi açısından olumsuz sonuçlar doğurabilir. Bu durumlarda, verileri sayfalara bölerek sunmak, yani “pagination” kullanmak, hem veritabanı hem de API performansını artırabilir.
Pagination, özellikle çok fazla veri içeren listeler üzerinde çalışırken önemlidir. Örneğin, kullanıcı listelerini döndürdüğünüz bir API’nin, binlerce kullanıcıyı tek bir yanıtla döndürmesi yerine, belirli sayıda kullanıcıyı sayfa sayfa döndürmesi, hem veritabanı yükünü azaltır hem de istemci tarafında gereksiz veri yüklemeyi önler. Bu yöntem, kullanıcılara daha hızlı ve duyarlı bir arayüz sunmanızı sağlar.
Prisma ile sayfalama işlemi yapmak oldukça kolaydır. skip ve take parametrelerini kullanarak, hangi verilerin döndürülmesi gerektiğini belirleyebilirsiniz. Aşağıda, kullanıcıları sayfalayarak nasıl döndürebileceğinizi gösteren bir örnek bulunmaktadır:
const users = await this.prismaService.user.findMany({
skip: offset,
take: limit,
select: {
uuid: true,
name: true,
email: true,
},
});
D) Lazy Loading: İlişkisel veritabanlarında, ilişkili verileri yalnızca ihtiyaç duyulduğunda yüklemek, API performansını önemli ölçüde artırabilir. Bu yaklaşım, özellikle büyük veri setleri ile çalışırken, yalnızca gerekli verilerin yüklenmesini sağlayarak sistem kaynaklarının daha verimli kullanılmasını mümkün kılar.
Lazy loading, tüm verileri tek seferde yüklemek yerine, sadece ihtiyaç duyulan verilere erişildiğinde bu verilerin yüklenmesi prensibine dayanır. Bu, veritabanında büyük ve karmaşık ilişkiler olduğunda, verimlilik açısından kritik bir fark yaratır. Örneğin, bir kullanıcıya ait profil bilgilerini sorgularken, her seferinde bu kullanıcıya bağlı tüm verileri çekmek yerine, sadece gerekli olanları yüklemek mantıklıdır.
Nest.js projelerinde Lazy Loading uygulamanın birkaç yolu vardır. Ancak, burada bahsedilen Lazy Loading, daha çok Angular’daki Lazy Loading kavramı ile karıştırılmamalıdır. Angular’daki Lazy Loading, modüllerin yüklenmesi ile ilgilidir; Nest.js’deki Lazy Loading ise veritabanı ilişkilerinin yönetimi ile alakalıdır.
E) Index kullanımı: Veritabanı sorgularınızın hızlı çalışmasını sağlamak için doğru alanlarda indeksler kullanmak çok önemlidir. Prisma’da bir indeks oluşturmak için @@index veya @unique anotasyonlarını kullanabilirsiniz. Örneğin, kullanıcıların email alanına göre sıkça sorgulandığı bir senaryoda, email alanına bir indeks eklemek mantıklı olacaktır
Test işlemlerinin başlatılması
İlk olarak, blog.io uygulamam için daha önce yazmış olduğum User Service içindeki GetAllUsers metodunu test etmek üzere kullanacağım. Bu metodun performansını değerlendirmek, kullanıcı verilerine erişim hızını ölçmek açısından önemli bir adım olacak. Ayrıca, projenin ilerleyen aşamalarında, Artillery.io kullanarak oluşturduğumuz load-test.yml dosyası ile test senaryolarımızı çeşitlendirmeyi ve farklı yük durumlarını simüle etmeyi planlıyorum.
Örnek load-test.yml dosyası
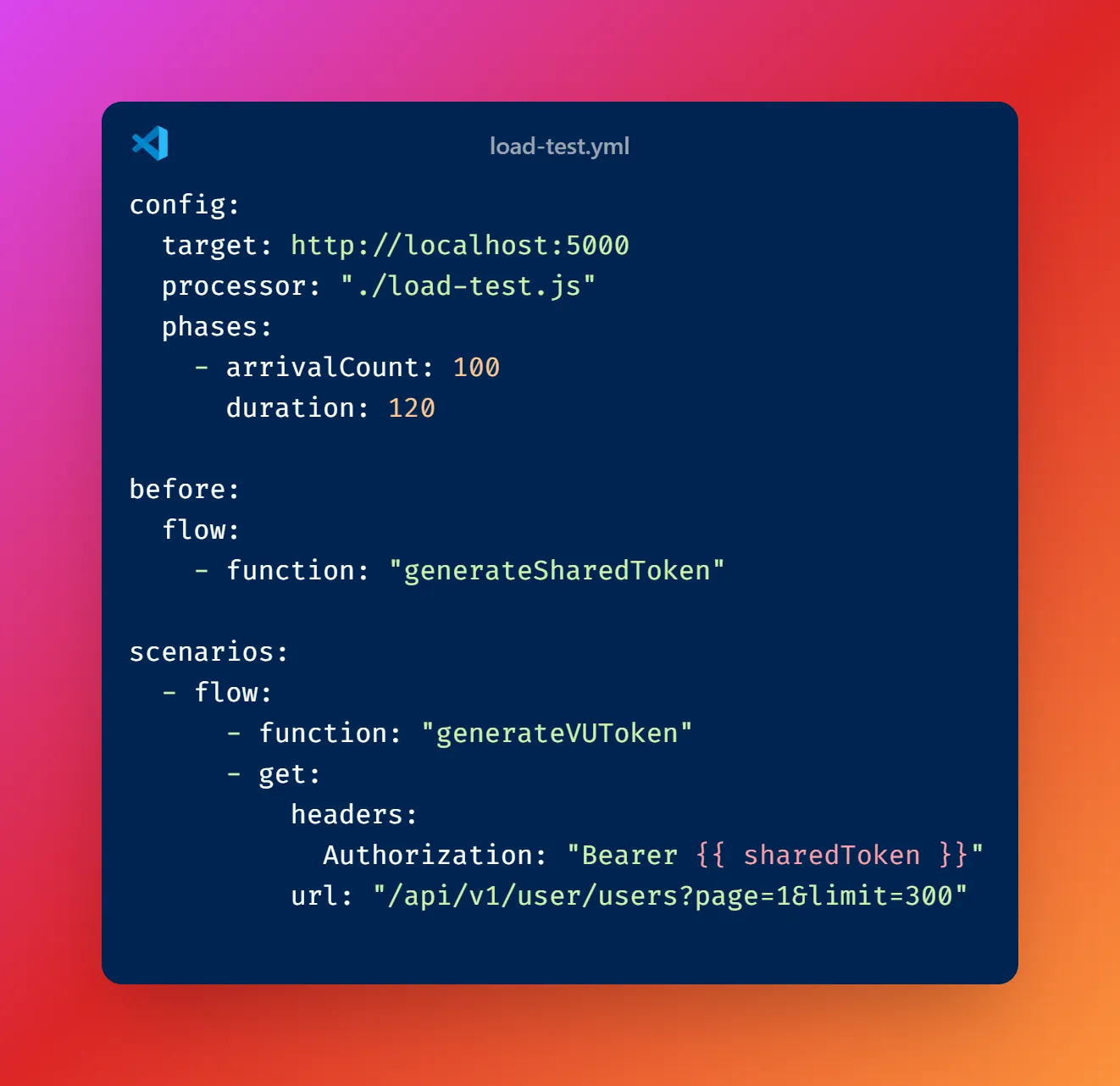
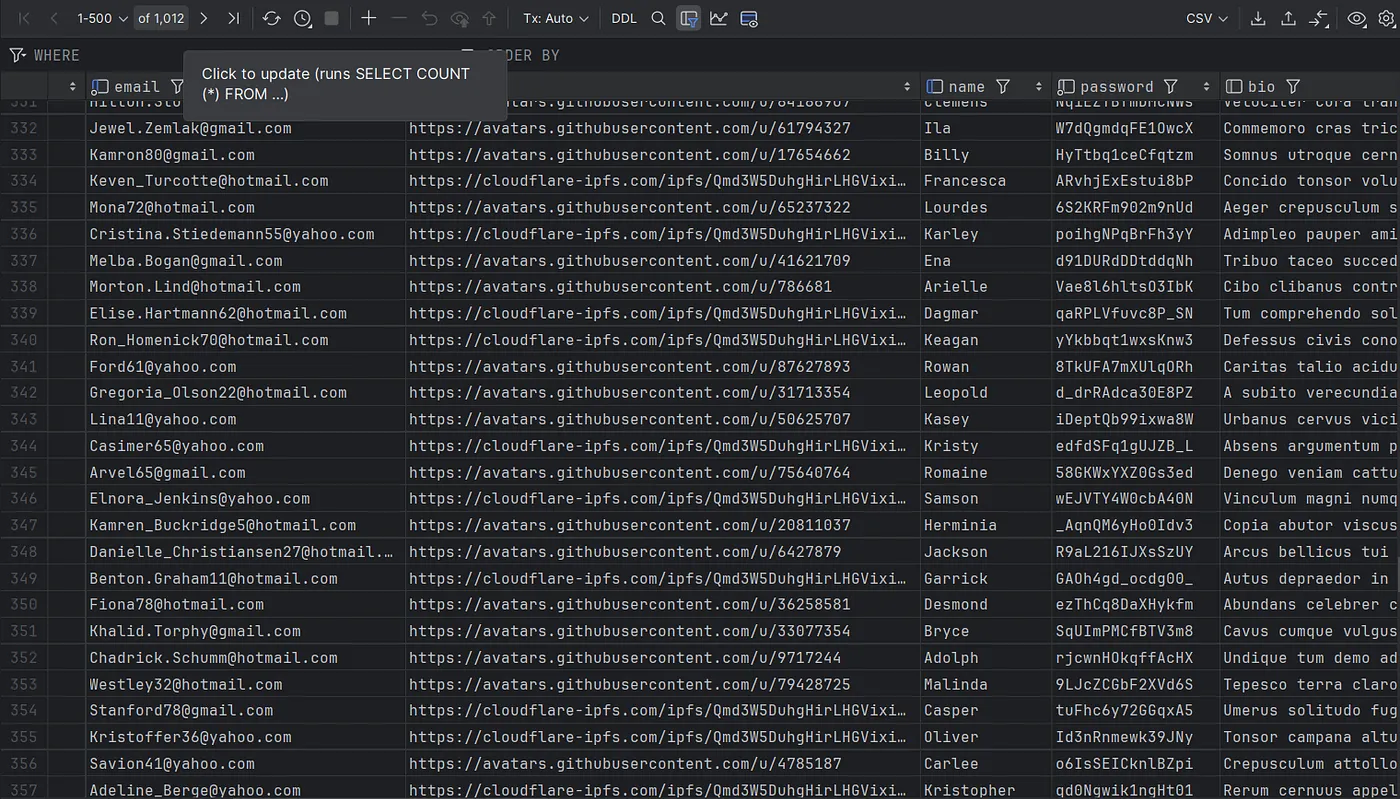
Ayrıca, PostgreSQL veritabanımızda faker.js kullanarak 1.000 sahte kullanıcı hesabı oluşturuyoruz. Bu kullanıcı hesapları, name, email, password, bio gibi alanları içeren bir user tablosunda yer alıyor. Bu sayede, uygulamanın performansını gerçekçi bir veri seti üzerinde test edebilir ve iyileştirmelerimizin etkisini daha doğru bir şekilde ölçebiliriz.
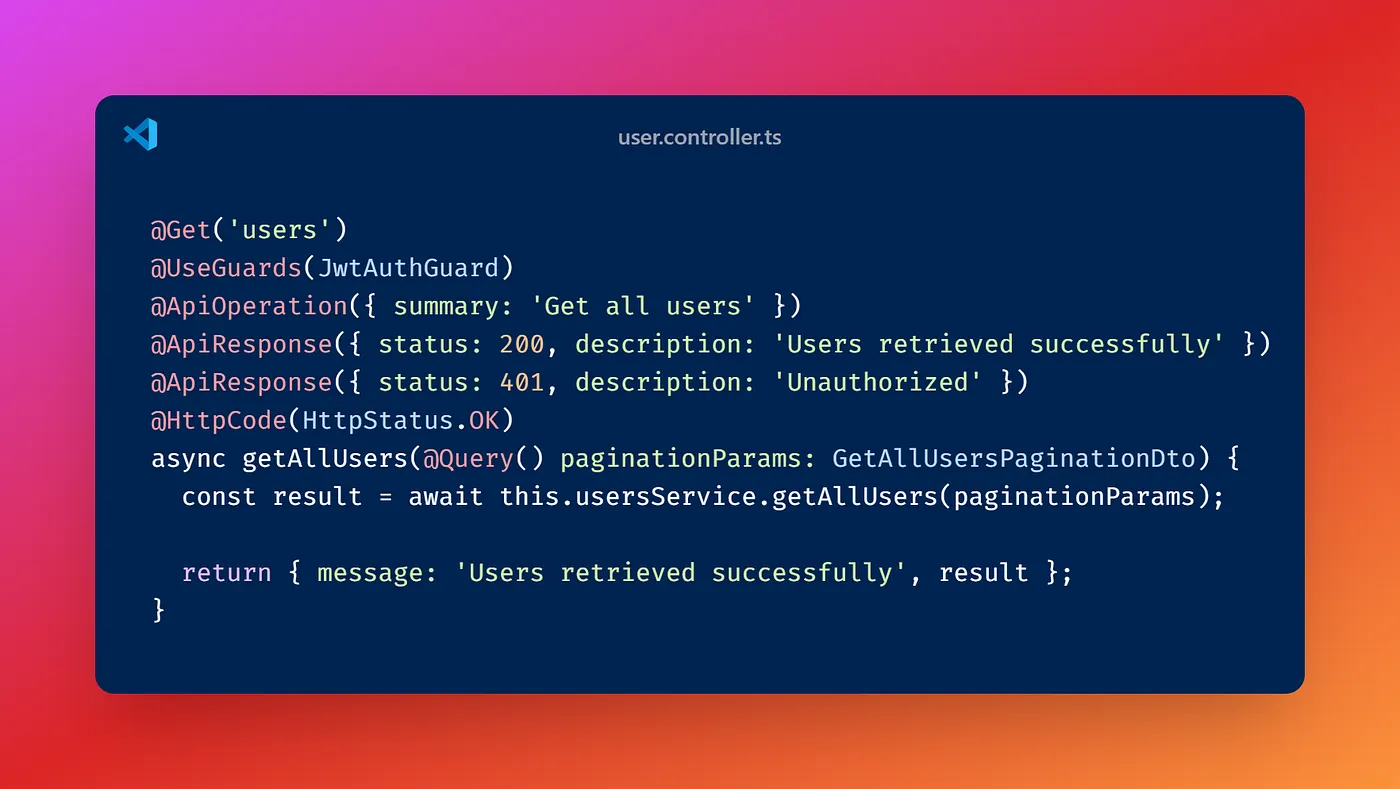
API’mizi, sayfalama ve sınırlandırma parametreleri ile birlikte kullanarak, belirli bir sayfadaki kullanıcıları çekmek için aşağıdaki örneği kullanıyoruz:
GET "/api/v1/user/users?page=1&limit=300"
Bu API, birinci sayfadan başlayarak 300 kullanıcıyı döndürecek şekilde yapılandırdık. Bu örnek, uygulamanın kullanıcı verilerini nasıl işlediğini ve performansını değerlendirmek için iyi bir temel sunuyor.
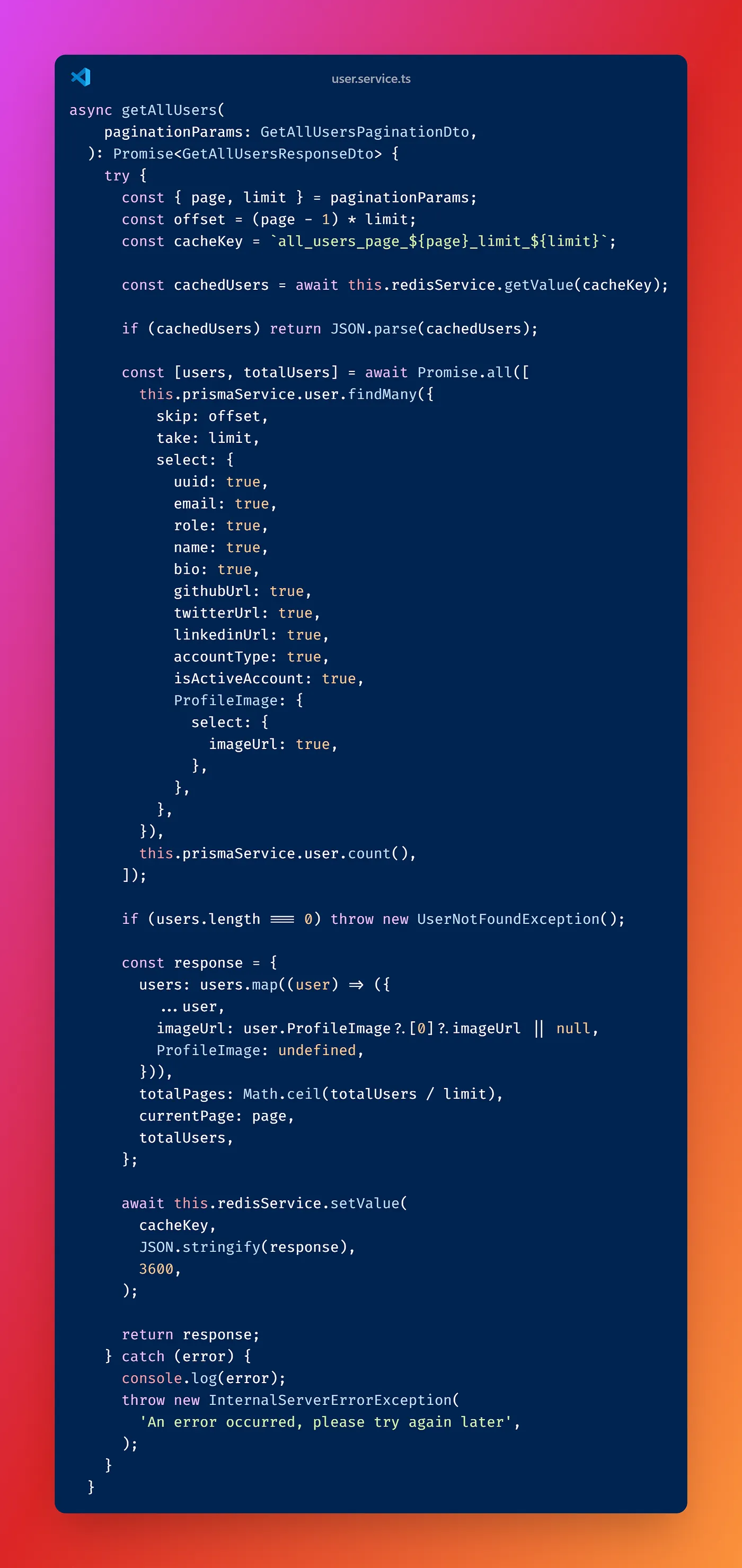
Bu serviste, user bilgisi öncelikle Redis önbelleğinde aranıyor. Eğer Redis üzerinde bu kullanıcı bilgisi mevcut değilse, veritabanından sorgulama yapılır ve elde edilen sonuç Redis'e kaydedilerek gelecekteki sorgular için önbelleğe alınır. Bu yöntem, sık erişilen kullanıcı verilerinin hızlı bir şekilde sunulmasını sağlar ve veritabanı sorgularının sayısını minimize eder, böylece API performansını artırır.
Artillery.io ile kapsamlı testlere başlamadan önce, Postman ile bir test gerçekleştirerek sürece başlayalım. Bu ilk testte, Redis’te henüz herhangi bir önbellek verimiz bulunmadığı için, API doğrudan veritabanı ile iletişime geçerek kullanıcı bilgilerini sorgulayacak. Bu, uygulamanın Redis önbelleği devreye girmeden önceki performansını ölçmek açısından önemli bir adım olacak.
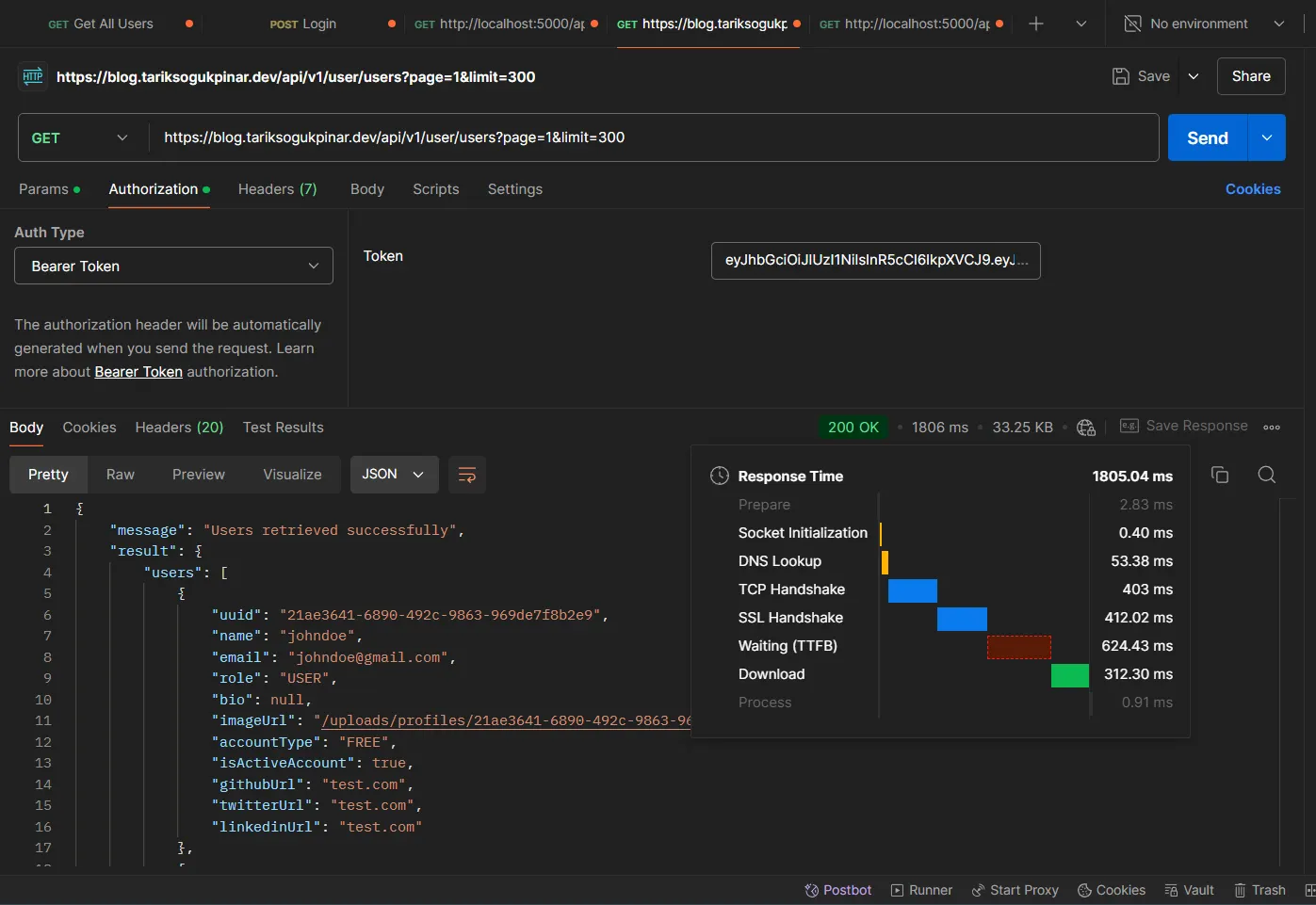
API’ye ilk defa istek attığımızda, ortalama “1805.04 ms” time alıyoruz. Şu anda, kullanıcı bilgisi tamamen veritabanından geliyor. Burada, konunun başında belirttiğimiz gibi, bu GET isteği öncelikle Redis cache’ine bakıyor. Eğer cache boş ise herhangi bir key değeri tutulmuyor önce veritabanına gidip, daha sonra ise bu datayı cache’liyor, yani Redis içerisine set ediyor.
Tekrar çalıştırdığımızda ise, response değerinin “977.23 ms” kadar düştüğünü görebiliriz. Böyle bir testte, environment ortamımız Ubuntu bir sunucu üzerinde Docker ile çalışıyor. Sunucu lokasyonumuz Türkiye ve istek yapılan ülke ise Tayland :)
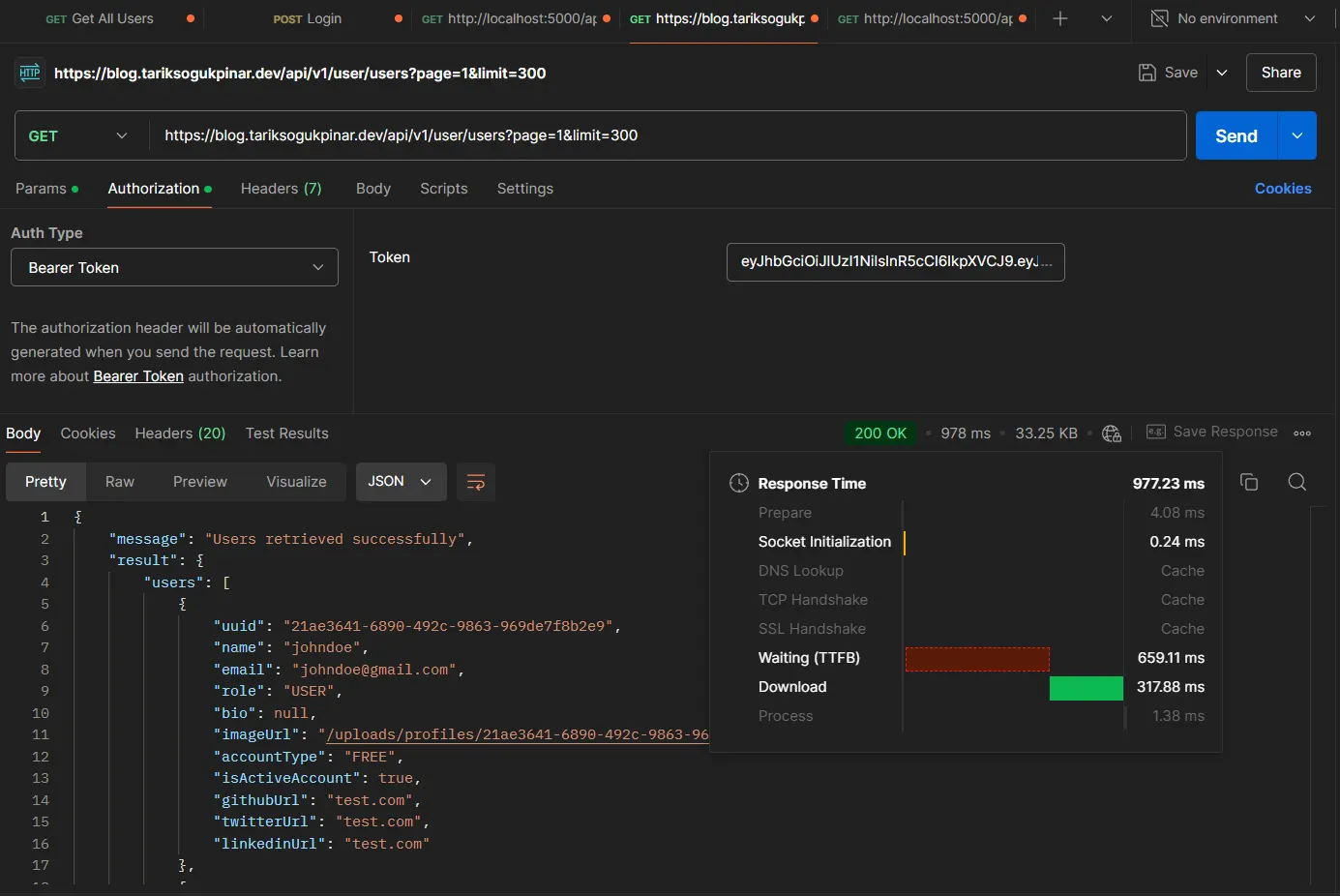
Postman ile yaptığımız temel test süreci burada sona eriyor. Şimdi, HTTP testlerini Ubuntu sunucumuz üzerinde Artillery.io kullanarak daha kapsamlı ve gerçekçi bir şekilde gerçekleştirelim. Artillery.io, API’mizin yüksek yük altındaki performansını ölçmemize ve gerçek dünya senaryolarına daha yakın testler yapmamıza olanak tanıyacak.
Bunu yapmak için, öncelikle Docker container’ımıza şu komutla erişebiliriz:
docker exec -it fb7d83731e73 /bin/bash
Container içerisine girdikten sonra, Artillery.io testimizi başlatmak için aşağıdaki komutu çalıştırabiliriz:
artillery run load-test.yml
```
Şimdi, `load-test.yml` dosyamıza daha fazla API ekleyelim ve testimizi tekrar çalıştıralım. Bu adım, farklı API uç noktalarının performansını aynı anda değerlendirerek uygulamanın genel performansını daha geniş bir perspektiften analiz etmemizi sağlayacak.

Güncel `load-test.yml` dosyamız şu şekilde yapılandırılmış durumda. Şimdi, bu yapılandırma ile testimizi çalıştıralım ve sistemimizi yük altında test edelim. Bu testte, her bir API'ye 50 saniye boyunca saniyede 50 istek gönderiliyor (duration ve arrivalCount değerlerimiz). Testin sonunda elde ettiğimiz sonuçlar ise şöyle:

Test sonucunda, minimum 6 ms, maksimum 474 ms ve ortalama 104 ms gibi bir yanıt süresi elde ediyoruz. Bu sonuçları değerlendirirken, sadece “users” API’sinde bir caching mekanizmasının devrede olduğunu unutmayalım.
Şimdi, senaryomuzu bir adım öteye taşıyarak uygulamamız üzerinde daha ağır bir yük testi yapalım. Bu amaçla, `load-test.yml` dosyamızı güncelleyelim. Güncellenmiş dosyayı çalıştırmak için şu komutu kullanacağız:
artillery run load-test.yml - output test_result.json
Bu komut, tüm test sonuçlarımızı bir `.json` dosyasına kaydedecek. Yeni konfigürasyonumuz, her saniyede 200 kullanıcı yaratarak bu kullanıcıların 120 saniye boyunca API'lere istek göndermesini sağlayacak.

Sonuç ve test açıklamaları

> 1. Test Süresi: Toplam 2 dakika sürmüş (60s).
>
> 2.800 adet başarılı (200 OK) yanıt alınmış.
>
> 3.Saniyede ortalama 7 istek yapılmış.
>
> 4.Toplam 800 istek gönderilmiş ve 800 yanıt alınmış.
>
> 5.Yanıt Süreleri:
> Minimum: 6 ms
> Maksimum: 419 ms
> Ortalama: 88.8 ms
>
> 6.Sanal Kullanıcı (VU) İstatistikleri
> 200 sanal kullanıcı oluşturulmuş ve tamamlanmış.
>
> 7. Oturum Süreleri
> Minimum: 250 ms
> Maksimum: 549.5 ms
> Ortalama: 367.6 ms
Sonuç: Bu test senaryosu, uygulamamızın orta seviyede bir yük altında nasıl performans gösterdiğini anlamamıza yardımcı oldu. Test süresi boyunca 2.800 başarılı yanıt alındı ve isteklerin tamamı başarıyla tamamlandı. Yanıt süreleri açısından, en düşük süre 6 ms, en yüksek süre ise 419 ms olarak ölçüldü, ortalama yanıt süresi ise 88.8 ms oldu. Bu da uygulamanın genel olarak hızlı ve tutarlı bir performans sergilediğini gösteriyor bizlere. Buraya kadar okuduğunuz için çok teşekkür ederim. Makalede bahsedilen bütün linkleri açıklamada bulabilirsiniz. Bir sonra ki yazılarda görüşmek üzere..
İlgili Kaynaklar;
[https://github.com/TarikSogukpinar/blog.io](https://github.com/TarikSogukpinar/blog.io)
[https://github.com/TarikSogukpinar/blog.io/blob/master/api/load-test.yml](https://github.com/TarikSogukpinar/blog.io/blob/master/api/load-test.yml)
[https://github.com/TarikSogukpinar/blog.io/blob/master/api/seeder.ts](https://github.com/TarikSogukpinar/blog.io/blob/master/api/seeder.ts)
[https://github.com/TarikSogukpinar/blog.io/blob/master/api/load-test.js](https://github.com/TarikSogukpinar/blog.io/blob/master/api/load-test.js)
[https://github.com/TarikSogukpinar/blog.io/blob/master/api/Dockerfile](https://github.com/TarikSogukpinar/blog.io/blob/master/api/Dockerfile)
[https://hub.docker.com/repository/docker/ledun/blogio-api/general](https://hub.docker.com/repository/docker/ledun/blogio-api/general)