
“System Design Interview” kitabını okurken aldığım notları bir seri halinde sizlerle paylaşmak istiyorum. 29 bölümden oluşan bu kitabın her bir bölümünü detaylı bir şekilde ele alarak, kendi deneyimlerim ve yorumlarımla harmanlayıp sizlere sunacağım.
Amacım, bu notların bir mini arşiv niteliği taşıması ve sizler için faydalı bir kaynak olması. Şimdiden keyifli okumalar diliyorum!
Chapter 1 — Scale From Zero to Millions of Users
Milyonlarca veya binlerce kullanıcıyı barındırabilecek sistemler tasarlamak oldukça zorlu bir süreçtir ve birçok farklı zorluk (challenge) içerir. Bu makale boyunca, sistem tasarımı süreçleri hakkında detaylı bilgiler edineceğiz.
Karmaşık ve ölçeklenebilir bir sistemin inşası genellikle standart adımlarla başlar. İlk aşamada, her şeyin tek bir sunucu üzerinde çalıştığı bir yapı görürüz: web servisi, veritabanı, önbellek (cache), kuyruk (queue) ve diğer bileşenler tek bir noktada birleştirilmiştir.
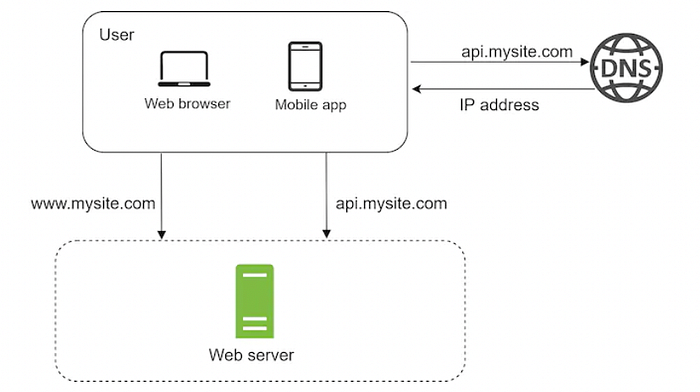
-
Kullanıcılar web sitelerine api.mysite.com gibi bir domain ile erişirler.
-
IP adresi tarayıcıya veya istek yapılan uygulamaya döndürülür.
-
IP adresi alındıktan sonra ise http istekleriniz web sunucuza yönlendirilir.
-
Web server HTML veya JSON yanıtlarını döndürür.
Web sunucuza gelen trafik 2 kaynaktan gelir: Web Application ve Mobile Application
“Database”
Tasarladığımız sistemde kullanıcı sayısı artmaya başladıkça, tek bir sunucunun performansı yetersiz hale gelebilir. Bu noktada, web ve mobil sunucularını birbirinden ayırmak, bu sunucuların bağımsız bir şekilde ölçeklendirilmesine olanak tanır. Böylece, sisteminiz artan talebi daha verimli bir şekilde karşılayabilir ve performans sorunlarının önüne geçilebilir.
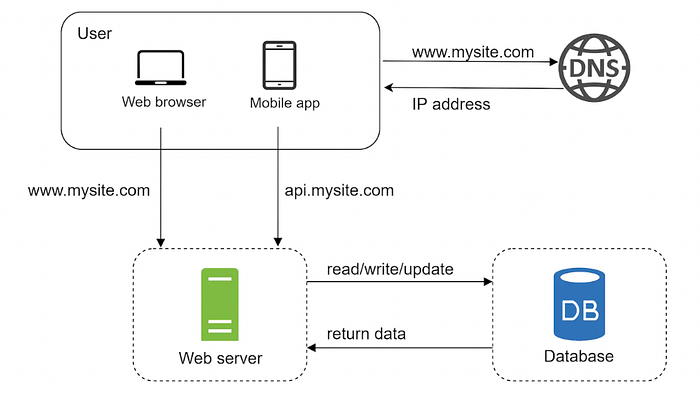
Hangi veritabanını kullanmalıyız?
Bu sorunun cevabı tamamen iş gereksinimlerinize bağlıdır. Ancak, seçim yaparken geleneksel ve uzun süredir kullanılan ilişkisel veritabanları (Relational Database) ile son yıllarda popülerliği artan ilişkisel olmayan (NoSQL) veritabanları arasında bir tercihte bulunabilirsiniz.
İlişkisel Veritabanları (RDBMS)
Relational Database Management Systems (RDBMS), SQL veritabanları olarak da adlandırılabilir. Günümüzde en popüler ve yaygın kullanılan örnekler arasında PostgreSQL, MySQL ve Oracle yer almaktadır. RDBMS, JOIN gibi güçlü sorgulama işlemlerini SQL dilini kullanarak gerçekleştirebilmenize olanak tanır. Bu özellik, karmaşık veri yapılarında ilişkileri yönetmek için oldukça faydalıdır.
İlişkisel Olmayan Veritabanları (NoSQL)
NoSQL olarak adlandırılan ilişkisel olmayan veritabanları, daha esnek ve ölçeklenebilir bir veri yönetimi sağlar. Günümüzde popüler NoSQL veritabanları arasında MongoDB, Cassandra, CouchDB ve DynamoDB bulunmaktadır. Bu veritabanları, kullanım amacına göre şu dört gruba ayrılabilir:
- Key-Value Stores
- Graph Stores
- Column Stores
- Document Stores
NoSQL veritabanlarında JOIN gibi işlemler genellikle desteklenmez, ancak bu eksiklik, performans ve ölçeklenebilirlik açısından avantaj sağlayabilir.
Hangi Veritabanını Seçmelisiniz?
Çoğu geliştirici için ilişkisel veritabanları (RDBMS), projelerde yaygın olarak tercih edilir. Bununla birlikte, projenizin gereksinimlerine bağlı olarak NoSQL veritabanları daha uygun bir seçenek olabilir. Özellikle aşağıdaki senaryolarda NoSQL veritabanlarını tercih etmeniz mantıklı olacaktır:
*Uygulamanızda son derece düşük gecikme sürelerine ihtiyacınız var ise
*Her hangi bir ilişkili veri yapınız yok ise
*Veri bütünlüğünün ve doğruluğunun çokta önemli olmadığı durumlarda
Vertical Scaling vs Horizontal Scaling
Vertical Scaling (Dikey Ölçeklendirme)
Dikey ölçeklendirme, “scale up” olarak da adlandırılır ve mevcut sunucularımıza daha fazla kaynak (CPU, RAM vb.) ekleme anlamına gelir. Bu yöntem, fiziksel olarak sunucuların gücünü artırmayı ifade eder.
Horizontal Scaling (Yatay Ölçeklendirme)
Yatay ölçeklendirme, “scale out” olarak bilinir ve sunucu havuzuna yatay bir şekilde daha fazla sunucu eklemek anlamına gelir. Bu yöntem, sistemin kapasitesini artırmak için birden fazla sunucuyu birbirine bağlayarak çalışmayı sağlar.
Ne Zaman Hangi Ölçeklendirme?
Web sitenizdeki trafik düşük olduğunda, vertical scaling harika bir seçenek olabilir. Ancak, bu yöntemin ciddi sınırlamaları ve dezavantajları vardır:
- Kaynak Sınırları: Bir sunucuya sınırsız CPU veya RAM eklemek mümkün değildir. Fiziksel limitler her zaman mevcuttur.
- Redundancy ve Failover Eksikliği: Dikey ölçeklendirme yapılan sistemlerde genellikle tüm servisler tek bir sunucu üzerinde çalışır. Bu sunucuda bir sorun meydana geldiğinde, tüm servisler kesintiye uğrar.
Bu nedenlerle, büyük ölçekli uygulamalarda horizontal scaling, dikey ölçeklendirmenin sınırlamalarını aşmak ve yüksek maliyetlerden kaçınmak için daha fazla tercih edilir. Yatay ölçeklendirme, sisteminizi birden fazla sunucuya yayarak daha iyi yük dengelemesi (load balancing), yüksek erişilebilirlik (high availability) ve kesintisiz çalışma sağlar.
Load Balancer
Load Balancer sunucularına gelen trafiği dengeli bir şekilde dağıtmak için kullanılır.
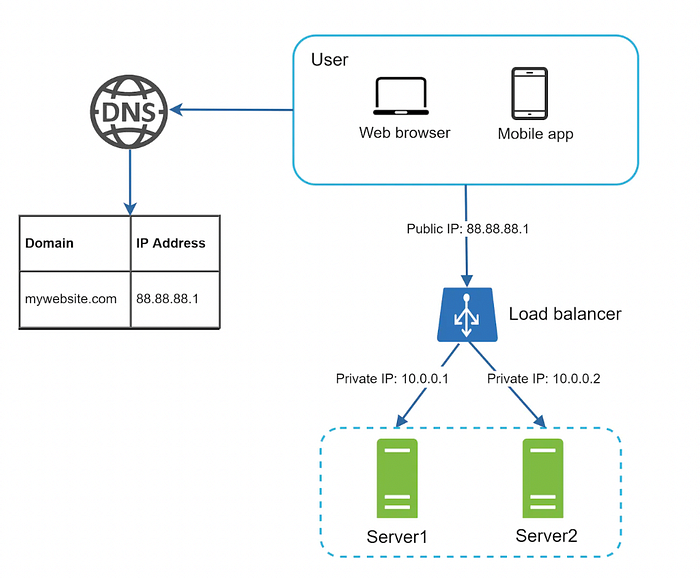
Bu yaklaşım sayesinde web sunucularındaki IP adresleri artık doğrudan erişilebilir olmayacaktır. Daha güvenli bir yapı (setup) oluşturmak için özel IP adresleri kullanılır. Böylece, web sunucularınız internete doğrudan maruz kalmaz ve dışarıdan gelen saldırılara karşı daha korunaklı hale gelir.
Eğer Server 1 offline olursa, tüm trafik yükü otomatik olarak Server 2'ye yönlendirilir. Bu, web sunucularınızın kapalı kalma süresini (downtime) en aza indirir ve servislerinizin kesintisiz bir şekilde çalışmaya devam etmesini sağlar.
Eğer web trafiğiniz hızla artıyorsa ve mevcut tasarımınıza daha fazla sunucu eklemeniz gerekiyorsa, bu noktada load balancer devreye girer. Load balancer, gelen trafik yükünü sunucular arasında başarıyla dağıtarak sistemin verimli bir şekilde çalışmasını sağlar. Bu sayede hem performans sorunlarının önüne geçilir hem de ölçeklenebilir bir yapı elde edilir.
Database Replication
Veritabanı replikasyonu (database replication), genellikle master/slave kavramı üzerine şekillenir. Bu yapı, birçok veritabanı sisteminde kullanılan yaygın bir yöntemdir.
- Master Database: Genellikle yalnızca yazma (write) işlemlerini destekler. Tüm insert, delete ve update gibi veri değiştirme işlemleri doğrudan master veritabanına gönderilir.
- Slave Database: Master veritabanından verilerin kopyalarını alır ve yalnızca okuma (read) işlemlerini destekler.
Bir uygulamanın iş gereksinimlerine bağlı olarak, okuma işlemleri genellikle yazma işlemlerinden daha sık gerçekleştirilir. Bu nedenle, slave veritabanlarının sayısı genellikle master veritabanlarından daha fazladır. Bu yapı, okuma yükünün birden fazla sunucuya dağıtılmasını sağlayarak performansı artırır.
Bu örnekte, bir master veritabanına bağlı birden fazla slave veritabanı örneği yer almaktadır. Bu yapı sayesinde, uygulama okuma işlemlerini birden fazla slave veritabanına yönlendirerek yük dengesini sağlar ve ana veritabanının aşırı yüklenmesinin önüne geçer.
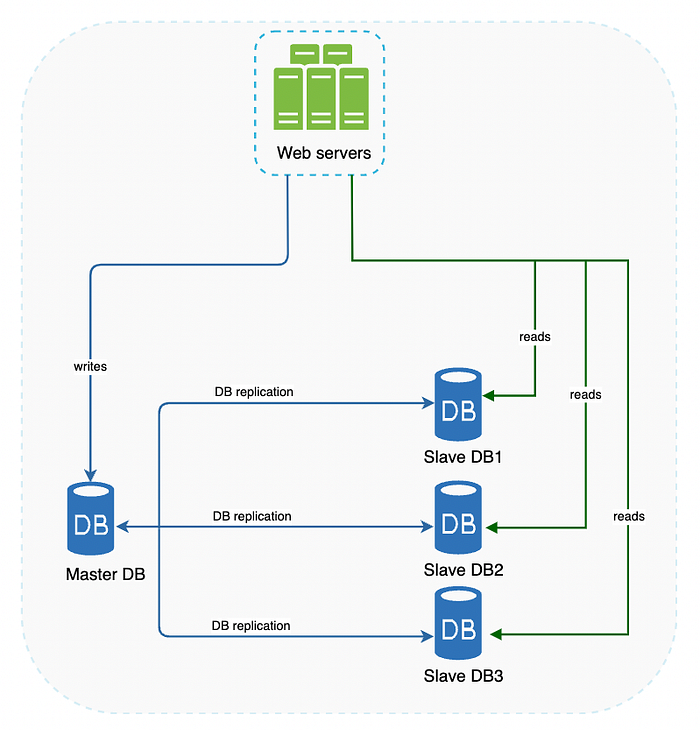
Database Replication Avantajları
- Daha İyi Performans:
Master-slave modelinde, tüm yazma ve güncelleme işlemleri master node üzerinde gerçekleşirken, okuma işlemleri slave nodelar arasında dağıtılır. Bu yaklaşım, okuma işlemlerinin paralel olarak işlenmesine olanak tanır ve sistem performansını önemli ölçüde artırır. - Güvenilirlik:
Veritabanı sunucularında herhangi bir problem yaşandığında veya veri kaybı riski oluştuğunda, verileriniz birden fazla sunucuda replikasyon ile çoğaltıldığından, veri kaybı konusunda endişelenmenize gerek kalmaz. - Yüksek Erişilebilirlik (High Availability):
Verileriniz birden fazla node üzerinde replikasyon yoluyla çoğaltıldığı için, sunuculardan biri çevrimdışı olsa bile diğer sunucular üzerinden erişim sağlanabilir. Bu durum, web sitenizin veya uygulamanızın kesintisiz çalışmasını sağlar.
Veritabanlarından Biri Çevrimdışı Olursa Ne Olur?
Daha önce load balancer kullanarak bir sistemin erişilebilirliğini (availability) nasıl artırabileceğimizi tartışmıştık. Burada aynı soruyu veritabanı özelinde ele alıyoruz:
- Bir Slave Database Offline Olursa:
Eğer sisteminizde yalnızca bir adet slave veritabanı varsa ve bu veritabanı çevrimdışı olursa, okuma işlemleri geçici olarak master veritabanına yönlendirilir. Sorun giderildiğinde, slave veritabanı eski işlevine geri döner.
Birden fazla slave veritabanına sahipseniz, okuma işlemleri diğer slave nodelara yönlendirilir. Yeni bir slave node, çevrimdışı olanın yerini alabilir. - Master Database Offline Olursa:
Master veritabanı çevrimdışı olduğunda, bir slave veritabanı geçici olarak master olarak seçilir. Tüm veritabanı işlemleri (yazma ve güncelleme dahil) bu yeni master veritabanında yürütülür. Ancak, özellikle üretim (production) ortamında, slave veritabanındaki veriler her zaman güncel olmayabilir. Bu nedenle, bu tür bir aktarım senaryosu daha karmaşık bir yapı ve ek düzenlemeler gerektirebilir.
Cache
Cache, bellekte geçici olarak tutulan verilerin daha hızlı bir şekilde sunulmasını sağlayan bir depolama alanıdır. Web sitenize bir istek (request) geldiğinde, ilgili verileri her seferinde veritabanından sorgulamak uygulamanızın performansını olumsuz etkileyebilir. Bunun yerine, sık sık değişmeyen veya sıkça kullanılan verileri cache üzerinde tutarak, performansı önemli ölçüde artırabilirsiniz.
Cache Tier (Cache Katmanı)
Cache katmanı, veritabanına kıyasla çok daha hızlı olan bir geçici veri depolama katmanıdır. Bu katman, özellikle yüksek performans gerektiren uygulamalarda sıkça tercih edilir.
Cache Layer Kullanmanın Avantajları:
- Daha İyi Performans:
Sık kullanılan verilere daha hızlı erişim sağlanır ve uygulama tepki süresi azalır. - Veritabanı Yükünün Azaltılması:
Veritabanına yapılan sorgu sayısı önemli ölçüde düşer, bu da veritabanı sunucularının daha verimli çalışmasına olanak tanır. - Bağımsız Ölçeklenebilirlik:
Cache katmanı, sistemden bağımsız olarak ölçeklenebilir. Bu, özellikle artan trafik karşısında esnek bir çözüm sunar.
Cache Kullanım Senaryoları:
- Sıkça kullanılan ancak nadiren değişen veriler (örneğin, kullanıcı profil bilgileri, statik içerikler).
- Veritabanı üzerindeki yoğun sorguların azaltılması gereken durumlar.
- Okuma ağırlıklı işlemler yapan sistemler.
Cache katmanı olarak genellikle Redis, Memcached gibi yüksek performanslı çözümler kullanılır. Bu çözümler, uygulamanızın ölçeklenebilirliğini ve hızını artırmak için etkili bir şekilde entegre edilebilir.

Cache Kullanım Süreci ve Stratejiler
Bir istek (request) geldiğinde, cache katmanı önce istenilen cevabın ön bellekte olup olmadığını kontrol eder. Eğer cevap ön bellekte mevcutsa, doğrudan cache üzerinden yanıt döner. Ancak, istenilen veri ön bellekte yoksa sorgu veritabanına yönlendirilir ve elde edilen sonuç cache’e kaydedilir. Bu strateji, read-through olarak adlandırılır.
Cache Kullanırken Dikkat Edilmesi Gerekenler
- Veri Türleri:
Cache, sıkça okunan ve nadiren değişen veriler için idealdir. Ancak, ön bellekte depolanan verilerin geçici olduğunu unutmayın. Örneğin, bir cache sunucusu yeniden başlatıldığında, ön bellekteki tüm veriler kaybolabilir. Bu nedenle, kritik veya kalıcı veriler için cache kullanımı uygun değildir. - Expiration Policy (Geçerlilik Süresi):
Ön bellekte depolanan veriler için bir expiration policy (geçerlilik süresi) tanımlamak iyi bir uygulamadır. Bu politika, belirli bir süre sonra ön bellekteki verilerin otomatik olarak kaldırılmasını sağlar.
- Çok kısa süreli expiration: Veriler sık sık ön bellekten silinir ve tekrar yüklenir, bu da performans kaybına neden olabilir.
- Çok uzun süreli expiration: Ön bellekteki veriler güncelliğini yitirebilir ve eski bilgilerle sonuç dönebilir.
Optimal bir expiration süresi belirlemek, sistemin performansı ve veri doğruluğu açısından kritik öneme sahiptir.
Consistency (Tutarlılık):
Cache ve veritabanı arasında tutarlılığı sağlamak önemli bir zorluktur. Veri değişiklikleri genellikle cache ve veritabanında aynı anda gerçekleşmediği için tutarsızlıklar oluşabilir.
Çoklu Bölge (Region) Kullanımı: Eğer cache işlemleri birden fazla bölgede gerçekleştiriliyorsa, tutarlılığı sağlamak daha da karmaşık hale gelebilir.
Bu konuyla ilgili daha fazla bilgi edinmek için “Scaling Memcache at Facebook” adlı makaleye göz atabilirsiniz.
CDN statik içerik sunmak için kullanılan coğrafi olarak dağıtık sunuculardan oluşan bir ağdır. CDN sunucuları resim, video, CSS, JavaScript dosyaları gibi statik içerikleri önbelleğe alır.
Dinamik içerik önbelleğe alma nispeten yeni bir kavramdır ve bu kitabın dışındadır.
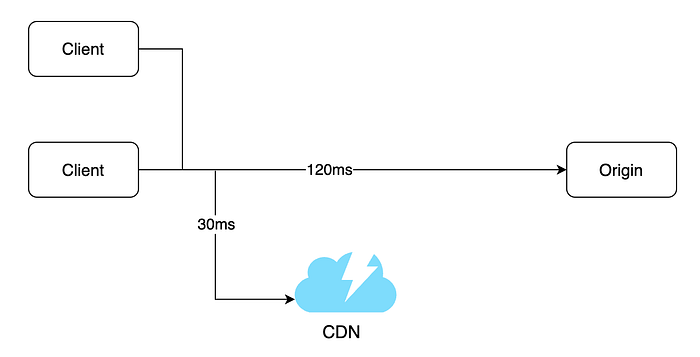
CDN’nin yüksek levelde nasıl çalışır: Bir kullanıcı bi web sitesini ziyaret ettiğinde kullanıcıya en yakın CDN sunucusu statik bir içerik sunar. Kullanıcılar CDN sunucusundan ne kadar uzaktaysa web sitesi o kadar yavaş yüklenir. Örneğin CDN sunucuları San Franciscodaysa Los Angelesta’ki kullanıcılar içeriği Avrupa’daki kullanıcılardan daha hızlı alacaktır.
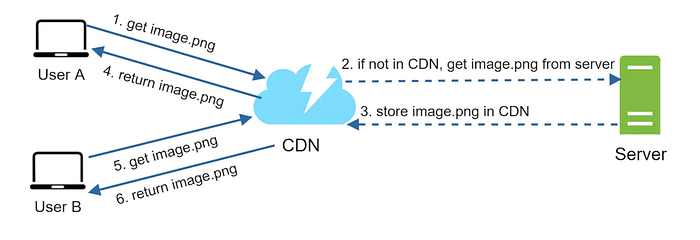
A kullanıcı bir resim URL’si kullanarak image.png görüntülemeye çalışır. URL’nin etki alanı CDN sağlayıcısı tarafından sağlanır.
CDN sunucusunun önbelleğinde image.png yoksa CDN sunucusu dosyayı bir web sunucusu veya Amazon S3 gibi çevrimiçi depolama alanı olabilecek kaynaktan ister.
Resimin ne kadar süreyle önbelleğe alındığını açıklayan HTTP header bilgisi TTL içeren CDN sunucusuna image.png döndürür.
CDN görüntüyü önbelleğe alır ve A kullanıcısına döndürür. Görüntü TTL’nin süresi dolana kadar CDN’de önbelleğe alınmış olarak kalır.
B kullanıcısı aynı görüntüyü almak için bir istek gönderir
TTL’nin süresi dolmadığı sürece görüntü önbellekten getirilir.
CDN kullanırken dikkat edilmesi gerekenler
Cost : CDN’ler üçüncü taraf sağlayıcılar tarafından çalıştırılır ve CDN’ye gelen ve çıkan veri aktarımları için sağlayıcı firmaya ücretlendirilirsiniz. Çok kullanılmayan varlıkları önbelleğe almak önemli bir fayda sağlamayabilir. Bu tarz datalarınızı CDN’den taşımayı düşünebilirsiniz.
Settings an appropriate cache expiry: Ön bellek expire süresi doğru ayarlanması önemlidir eğer süre çok uzun ise data yenilenmemiş olabilir. Eğer çok kısa ise içeriğin kaynak sunuculardan CDN’e yeniden yüklenmesine neden olabilir.
CDN fallback: Web sitenizin CDN hatalarını yönettiğini değerlendirmelisiniz. Eğer geçici bir CDN kesintisi gerçekleşirse ise istemciler orgin kaynaktan veri isteyebilmelidir.
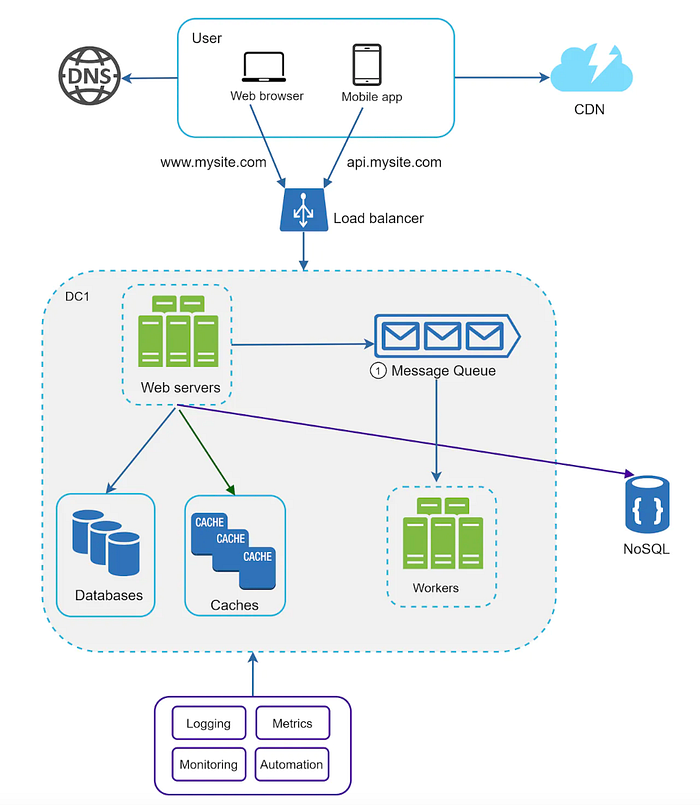
Message Queue
Mesaj kuyrukları, bellekte depolanan ve asenkron iletişimi destekleyen bir bileşendir. Bu sistemler, dayanıklı iletişim sağlar ve bir arabellek görevi görerek istekleri asenkron bir şekilde dağıtır.
Mesaj kuyruklarının mimarisi oldukça basittir. Producers veya publishers olarak adlandırılan servisler, mesajlar oluşturur ve bu mesajları mesaj kuyruğuna gönderir. Bu mesajlar, kuyruğun bir parçası haline gelir ve işlenmeyi bekler. Consumers veya subscribers olarak adlandırılan diğer servisler ise bu mesaj kuyruğuna bağlanır ve gelen mesajlara bağlı olarak tanımlanan işlemleri gerçekleştirir.
Producers mesajları kuyruğa bırakırken, consumers bu kuyruğa bağlanarak mesajları alır ve işler. Bu süreç tamamen asenkron bir şekilde yürütülür, böylece iş yükü eşit şekilde dağıtılabilir ve sistemlerin performansı artırılabilir.
Mesaj kuyrukları, iş yükünü dengeleme, gecikmeyi yönetme ve sistemler arasında asenkron iletişim sağlama gibi kritik görevler üstlenir. Örneğin, RabbitMQ, Apache Kafka ve Amazon SQS gibi popüler sistemler, farklı ölçeklerde bu işlevleri yerine getirmek için kullanılır.

Logging, Metrics ve Automation
Küçük ölçekli web siteleriyle çalışırken logging, metrics ve automation desteği faydalı olabilir ancak genellikle kritik bir gereklilik değildir. Ancak, sisteminiz büyüdüğünde ve büyük işletmelere hizmet vermeye başladığınızda bu araçlar vazgeçilmez hale gelir.
Logging:
Hata loglarını takip etmek, sistemdeki hataların ve sorunların tespit edilmesinde kritik bir rol oynar. Hata loglarını sunucu düzeyinde izleyebilir ve bu logları merkezi bir yerde toplayarak daha kolay bir şekilde arama ve izleme (monitoring) gerçekleştirebilirsiniz. Böylece, sistem sorunlarını hızlıca teşhis edip çözüm üretebilirsiniz.
Metrics:
Uygulamanızla ilgili çeşitli metrikler toplamak, sisteminizin durumu ve performansı hakkında değerli içgörüler sağlar. Metrikler, sistemin sağlık durumunu anlamanızı ve gerektiğinde iyileştirmeler yapmanızı mümkün kılar. Faydalı olabilecek metrik türleri şunlardır:
- Host-Level Metrics: CPU kullanımı, bellek (RAM) durumu, disk I/O gibi sunucu düzeyindeki metrikler.
- Aggregated-Level Metrics: Örneğin, veritabanı katmanının veya önbellek katmanının genel performansı gibi toplu düzeyde metrikler.
- Key Business Metrics: Günlük aktif kullanıcı sayısı, kullanıcı tutma oranı (retention), gelir gibi iş açısından kritik metrikler.
Automation:
Sisteminiz büyüyüp karmaşık hale geldikçe, üretkenliği artırmak ve operasyonel yükü azaltmak için otomasyon araçlarından faydalanmanız gerekebilir. Otomasyon, tekrar eden işlemleri azaltarak hem zaman kazandırır hem de hataları minimize eder.
Sürekli Entegrasyon (Continuous Integration):
Sürekli entegrasyon, her kod değişikliğinin otomasyon yoluyla doğrulandığı bir süreçtir. Bu, ekiplerin sorunları erken tespit etmesini ve çözüm sürecini hızlandırmasını sağlar. Sürekli entegrasyon, özellikle büyük ekiplerde yazılım kalitesini artırmak ve entegrasyon hatalarını minimize etmek için vazgeçilmez bir uygulamadır.
Otomasyonun Sağladığı Faydalar:
- Build, deploy ve süreç yönetimi gibi operasyonların otomatikleştirilmesi, geliştirici üretkenliğini önemli ölçüde artırır.
- Daha hızlı sürüm dağıtımı (deployment) ve hata tespiti sağlayarak sisteminizin genel verimliliğini artırır.
- İnsan hatasını azaltarak süreçlerin daha güvenilir ve tutarlı bir şekilde yürütülmesini sağlar.
Otomasyon araçları ve uygulamaları, karmaşık sistemlerde ekiplerin zamandan tasarruf etmesine ve daha verimli bir şekilde çalışmasına yardımcı olur.
Database Scaling
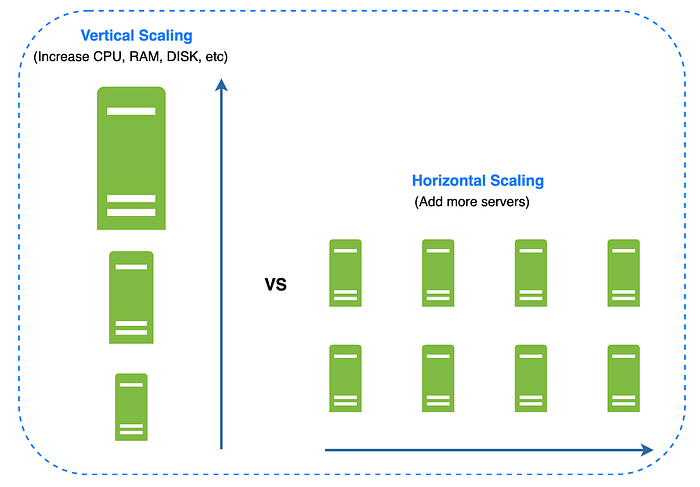
Veritabanı ölçeklendirme için iki temel yaklaşım bulunmaktadır: horizontal scaling ve vertical scaling.
Vertical Scaling (Dikey Ölçeklendirme)
Dikey ölçeklendirme, “scaling up” olarak da bilinir ve mevcut bir makineye daha fazla kaynak (CPU, RAM vb.) ekleyerek ölçeklendirme yapılması anlamına gelir. Örneğin, Amazon Relational Database Service (RDS) üzerinden 12 TB RAM’e sahip bir veritabanı sunucusu satın alabilirsiniz. Bu tür güçlü veritabanı sunucuları, çok büyük miktarda veriyi işleyebilir ve depolayabilir.
2013 yılında StackOverflow, aylık 10 milyondan fazla tekil ziyaretçiye hizmet veriyordu ve yalnızca bir ana veritabanına sahipti. Ancak, vertical scaling’in ciddi dezavantajları vardır:
- Donanımın fiziksel sınırları nedeniyle, sunucunuza ekleyebileceğiniz CPU veya RAM miktarı sınırlıdır.
- Geniş bir kullanıcı tabanınız varsa, tek bir sunucu genellikle yetersiz kalır.
- Tek bir sunucuya bağımlılık, single point of failure (tek hata noktası) riskini artırır.
- Vertical scaling maliyeti yüksektir; güçlü donanımlar, yatay ölçeklendirmeye kıyasla çok daha pahalıdır.
Horizontal Scaling (Yatay Ölçeklendirme)
Yatay ölçeklendirme, “scaling out” veya “sharding” olarak da bilinir. Bu yöntem, mevcut sisteme daha fazla sunucu eklenmesi anlamına gelir.
Horizontal scaling, büyük kullanıcı tabanlarına hizmet veren sistemlerde tercih edilir, çünkü:
- Daha fazla sunucu eklenerek kapasite artırılabilir.
- Tek bir sunucuya bağımlılık ortadan kalkar, bu da sistemi daha dayanıklı hale getirir.
- İş yükü, birden fazla sunucuya bölündüğü için performans daha verimli bir şekilde yönetilir.
Horizontal scaling’in uygulanması daha karmaşık olabilir, çünkü verilerin farklı sunuculara bölünmesi (sharding) ve veri tutarlılığının sağlanması gerekir. Ancak, bu yöntem uzun vadede hem maliyet hem de performans açısından genellikle daha avantajlıdır.
Sharding
Sharding, büyük veritabanlarını shard adı verilen daha küçük ve daha kolay yönetilebilir parçalara ayırma yöntemidir. Her shard, aynı veritabanı şemasını (schema) paylaşır, ancak her shard içindeki veriler, diğer shardlar için benzersizdir.
Bu yaklaşım, veritabanının yatay ölçeklendirilmesini sağlar ve sistemin performansını artırır. Sharding, özellikle büyük miktarda veriyi işleyen ve yüksek trafik alan sistemlerde kullanılır.
Örneğin, bir kullanıcı tablosu shardlara bölündüğünde, kullanıcıların bir kısmı bir shardda, diğer kısmı başka bir shardda depolanır. Bu sayede, sorgular belirli bir shard ile sınırlı kalabilir ve performans optimize edilmiş olur.
Sharding’in avantajları:
- Büyük veritabanlarının daha yönetilebilir hale gelmesi.
- Veritabanı sorgularının daha hızlı yanıt verebilmesi.
- Yüksek trafikli uygulamalarda ölçeklenebilirlik sağlanması.
Sharding’in uygulanması, verilerin bölünme stratejisi (örneğin, kullanıcı ID’sine göre bölme) gibi karmaşık yapılandırmalar gerektirebilir. Ancak, doğru şekilde uygulandığında, büyük veritabanlarının yönetimini ve performansını büyük ölçüde iyileştirir.
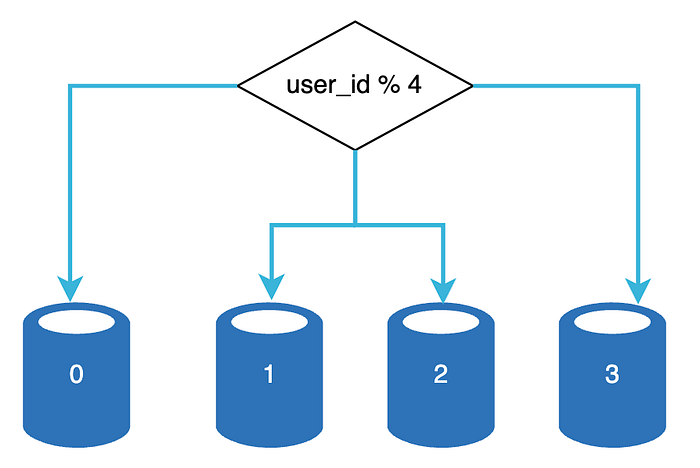
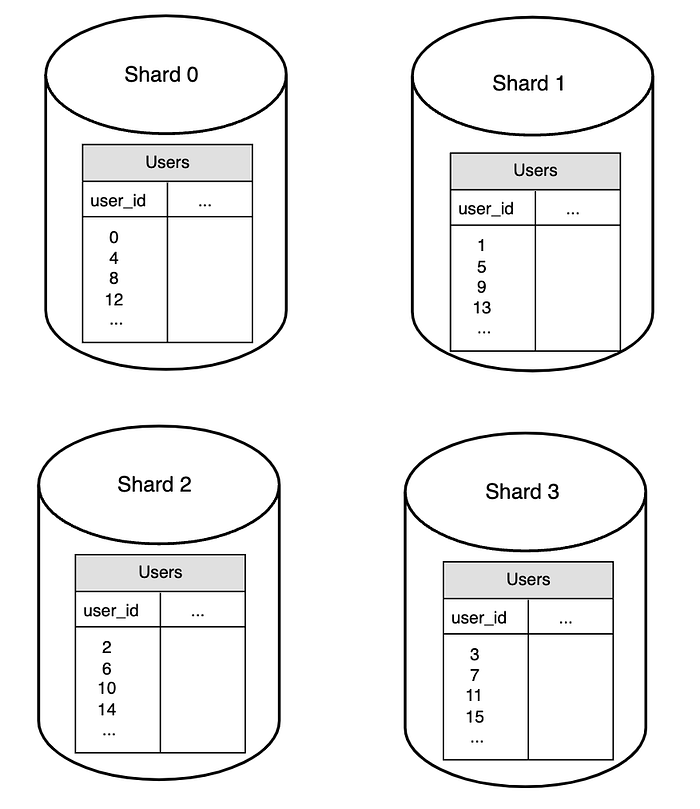
Sharding Stratejisi
Sharding stratejisi uygularken göz önünde bulundurulması gereken en önemli faktör, sharding anahtarının (sharding key) seçimidir. Sharding key, aynı zamanda partition key olarak da bilinir ve verilerin sistemde nasıl dağıtılacağını belirleyen bir veya daha fazla sütundan oluşur.
Örneğin, bir kullanıcı tablosunda user_id bir sharding key olarak kullanılabilir. Bu anahtar, veritabanı sorgularının doğru shard’a yönlendirilmesini sağlar ve verilerin verimli bir şekilde sorgulanmasına imkan tanır.
Sharding key seçerken dikkat edilmesi gereken en önemli kriterlerden biri, verilerin eşit olarak dağıtılabilmesini sağlamaktır. Eşit dağılım, her shard’ın dengeli bir yük altında çalışmasını ve performans sorunlarının önlenmesini garanti eder.
Ancak, sharding veritabanı ölçeklendirme için iyi bir teknik olsa da mükemmel bir çözüm değildir. Sharding, sisteme yeni karmaşıklıklar ve zorluklar getirir. Örneğin, veri yeniden dağıtımı gerektiğinde operasyonel yük artabilir veya shard’lar arası tutarlılığı sağlamak zorlaşabilir.
Millions of Users and Beyond
Bir sistemi ölçeklendirmek, tekrar eden ve yinelemeli bir süreçtir. Bu bölümde öğrendiğimiz teknikler, ölçeklendirme süreçlerinde temel bir rehber olarak kullanılabilir. Ancak milyonlarca kullanıcının ötesine geçmek için daha fazla ince ayar ve yeni stratejiler gerekir.
Örneğin, tüm sisteminizi optimize etmeniz, daha küçük ve bağımsız servislerden oluşan bir mimariye geçiş yapmanız gerekebilir. Bu bölümde ele alınan teknikler, yeni zorlukların üstesinden gelmek için güçlü bir temel oluşturmalıdır.
Milyonlarca Kullanıcıyı Desteklemek için Ölçeklendirme Önerileri
- Web katmanını stateless hale getirin: Web sunucularını durumdan bağımsız hale getirmek, yatay ölçeklendirmeyi kolaylaştırır.
- Her katmanda yedeklilik sağlayın: Sunucuların ve bileşenlerin yedekli bir yapıda çalışmasını sağlayarak hata toleransını artırın.
- Veriyi olabildiğince önbelleğe alın: Cache kullanarak veritabanı yükünü azaltın ve kullanıcıya hızlı yanıtlar sunun.
- Birden fazla veri merkezini destekleyin: Verilerinizi ve hizmetlerinizi coğrafi olarak dağıtılmış veri merkezlerine yayıp erişilebilirliği artırın.
- Statik varlıkları CDN’de barındırın: Resim, video, CSS gibi statik içerikleri CDN aracılığıyla kullanıcılarınıza daha hızlı ulaştırın.
- Sharding ile veri katmanını ölçeklendirin: Verilerinizi sharding stratejisiyle bölerek performansı artırın.
- Katmanları bireysel servislere ayırın: Mikroservis mimarisi kullanarak sistemi daha modüler ve yönetilebilir hale getirin.
- Sistemi izleyin ve otomasyon araçları kullanın: Sistem sağlığını izlemek ve süreçleri otomatikleştirmek için monitoring ve otomasyon araçlarından faydalanın.